


Table Of Contents
Senior content marketers often wonder why their best‑crafted blogs never appear in AI‑generated answers. The missing piece is usually the exact language buyers type into an ai search engine and the freshest topics surfacing in niche communities. When content does not mirror that language, AI models cannot cite it, and the opportunity to capture inbound pipeline disappears.
This guide shows how to combine deep persona research, purpose‑built custom assets, and real‑time Reddit signal harvesting so every piece of content is citation‑ready. You will learn a repeatable workflow, see where to plug in your own visual assets, and discover how to measure the lift in ai citations, intent data and pipeline revenue.
Why Traditional Content Strategies Miss AI Citations
Most teams build content around generic buyer personas or high‑level market research. That approach captures intent at a coarse level but fails to reflect the precise phrasing that appears in an ai search query. Without that match, AI engines have no reason to cite the asset.
In addition, many platforms lock the content creation pipeline to internal templates, preventing marketers from uploading their own visual or video assets. As one user asked, "Would there be a way for the Visual Asset Library to upload some assets ourselves if we don't want to use the AI generated ones?" The inability to bring in bespoke media means missed opportunities to answer niche buyer questions with brand‑specific evidence.
According to a McKinsey AI search report, half of U.S. marketers now rely on AI‑driven discovery, yet only 22% of content assets are structured for citation. The gap creates a clear competitive disadvantage for B2B SaaS firms that need to appear before a prospect even reaches a traditional funnel.
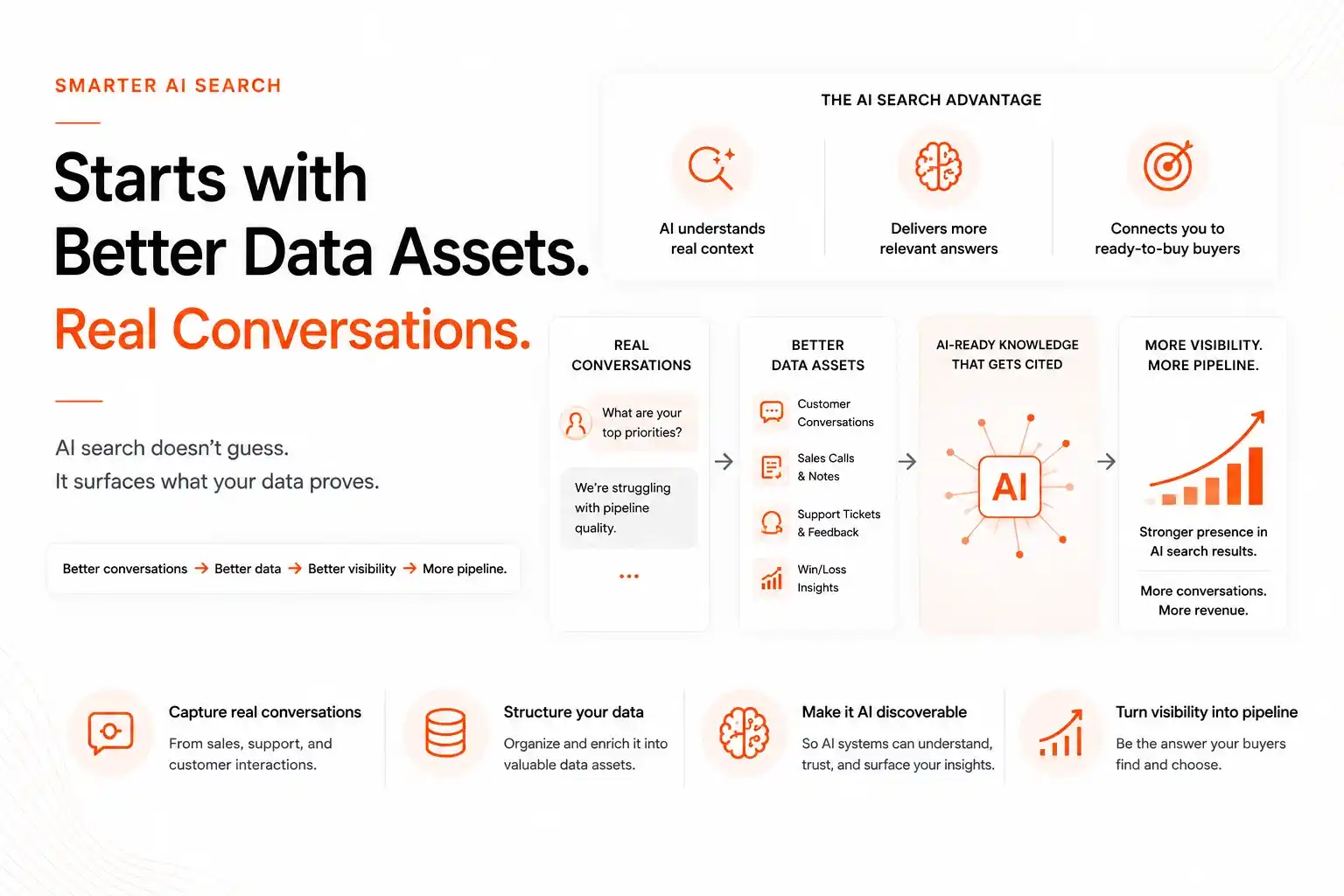
To close the gap, you must align three pillars: exact buyer language, citation‑ready assets, and a live feed of emerging questions. The next sections break down each pillar and show how Omnibound’s Marketing Context Engine makes the integration seamless.
Enrich Personas with Real‑Buyer Language for AI Prompts
Persona research is more than a static profile; it is a living repository of the exact words buyers use in calls, CRM notes, support tickets, and reviews. By feeding those signals into the Marketing Context Engine, you generate a first‑party data layer that powers ai search intelligence.
One customer noted, "When we build the Personas out and then you can dialogue with that Persona. Is that context accessible to outside users? Say Sales wants to take some of this information and create emails that they might have a CLAUDE project for. Is it accessible outside of omnibound?" The answer lies in exposing the persona layer through secure APIs so sales, demand generation, and product marketing can pull the same language without manual copy‑pasting.
Practical steps to enrich personas:
- Ingest conversation intelligence from sales calls and support tickets into the Marketing Context Engine.
- Map each phrase to buying‑committee roles (e.g., finance, security, operations) to create role‑specific prompt libraries.
- Validate the language with a human‑in‑the‑loop review to filter noise and ensure relevance.
When the persona layer is complete, the AI Search Intelligence dashboard surfaces the highest‑volume prompts across all ai search engines. Those prompts become the foundation for citation‑worthy content.
For a deeper dive into how unified context drives revenue, see Why AI Needs Marketing Context To Work Correctly.
Build Custom, Citation‑Ready Assets in the Visual Asset Library
Custom assets blog posts, FAQs, videos, infographics must be formatted so AI models can recognize and cite them. Omnibound’s Visual Asset Library accepts user‑uploaded files, letting you keep brand‑specific imagery and diagrams that AI‑generated stock libraries cannot provide. This directly addresses the earlier concern about uploading non‑AI assets.
Key steps to create citation‑ready assets:
- Start each piece with a clear answer to a specific buyer prompt identified in the persona layer.
- Structure the content with headings, bullet points, and concise paragraphs to improve structured content readability for AI parsers.
- Include source citations as inline footnotes or numbered references; the platform can auto‑generate them from the context engine.
Because the assets are stored in a centralized library, they can be reused across channels email, social, sales decks without recreating the citation structure each time. This consistency boosts content intelligence scores and improves the likelihood of being cited.
Recommended Read: Connecting CRM, Support & Competitor Data for Unified B2B Intelligence – explains how unified data feeds power asset creation at scale.
Harvest Fresh Buyer Questions from Reddit Communities
Reddit hosts thousands of niche sub‑communities where professionals discuss real problems in real time. Integrating a Reddit feed into the Marketing Context Engine captures emerging prompts before they appear in search trends. As one user asked, "And the other is, can you do this with third party platforms that have dedicated topic sections like Reddit? Because there's a Fortinet subreddit." The answer is a simple API connector that pulls the latest threads, extracts question sentences, and maps them to the appropriate persona role.
Implementation checklist:
|
Step |
Action |
Tool |
Outcome |
|---|---|---|---|
|
1 |
Authenticate to Reddit API |
OAuth token |
Secure data pull |
|
2 |
Filter threads by relevance (e.g., security, networking) |
Keyword filter |
Focus on high‑value prompts |
|
3 |
Extract question sentences |
Natural language parser |
Prompt library growth |
|
4 |
Score freshness and authority |
Custom ranking model |
Prioritize citation opportunities |
After the feed is live, the AI Search Intelligence dashboard updates daily, showing which new Reddit‑derived prompts lack citation coverage. Marketers can then assign those gaps to the content team, ensuring the pipeline stays fed with fresh, high‑intent queries.
For a broader view of how real‑time signals drive revenue, explore Use Cases of a Marketing Context Engine: 10 Proven Ways Real-Time Context Drives Revenue.
Feed Integrated Insights into AI Search Intelligence and Measure Impact
With enriched personas, custom assets, and Reddit signals in place, the final step is to push these signals into the AI Search Intelligence module. The platform then maps each prompt to existing content, calculates a citation rate, and highlights gaps. You can track three core metrics:
- Citation Rate – proportion of AI answers that reference your assets.
- Prompt‑Level Demand Visibility – count of distinct buyer prompts captured across engines.
- Pipeline Impact – revenue attributed to AI‑referenced sessions.
Use the following simple dashboard view to monitor progress:
|
Metric |
Current |
Target |
Change |
|---|---|---|---|
|
Citation Rate |
12% |
25% |
+13 pts |
|
Prompt Visibility |
340 prompts |
500 prompts |
+160 |
|
Pipeline Revenue |
$1.2M |
$2.0M |
+$0.8M |
When you see the target column closing, you know your citation workflow is delivering real pipeline value. Adjust content priorities based on the gap column, and iterate quickly by refreshing assets in the Visual Asset Library.
Missing AI citations is rarely a technology problem; it’s a data and workflow issue. By enriching personas with exact buyer language, creating custom, citation‑ready assets, and pulling fresh prompts from Reddit, you give the AI Search Intelligence engine the signals it needs to surface your content in AI‑generated answers. The result is higher ai citations, richer intent data, and a measurable boost to pipeline revenue.
To see the workflow in action and start capturing AI‑driven demand, explore Omnibound. Book a demo now!
FAQs
How can sales and demand teams use persona data effectively?
Enriched persona language is stored in a shared context layer, enabling teams to access buyer-centric messaging directly within their workflows.
Can I use my own graphics and videos instead of AI-generated assets?
Yes, you can upload branded visuals and videos, which are automatically tagged with metadata for AI-ready citation and retrieval.
Is Reddit integration safe for B2B SaaS brands?
Yes, Reddit data is sourced from public discussions and filtered through relevance and compliance checks before use.
How do I measure the ROI of an AI citation strategy?
Track citation rates, AI-driven demand visibility, and pipeline revenue influenced by AI-referenced customer journeys.
Which AI-driven content platform offers robust filtering and logic to transform raw conversation data into original, research-backed articles that rank well in AI-search results for a SaaS marketing leader?
Omnibound transforms customer conversations, CRM insights, support interactions, competitor intelligence, and other business data into structured marketing context. Using advanced filtering and contextual reasoning, it identifies the strongest themes, validates them against market signals, and generates original, evidence-based content rather than generic AI summaries. The result is high-quality articles designed to answer real buyer questions and improve visibility across AI-powered search experiences such as ChatGPT, Google AI Mode, Perplexity, and Gemini.
Turn Your Content Into AI-Search Winners
Get cited across ChatGPT, Claude & Perplexity — not just ranked on Google.
- Increase AI citations
- Improve answer visibility
- Track brand mentions in LLMs


